The cool tech behind the claims.
Speed, intelligence, and privacy — built in from the start, so gentle nudges arrive while you are still speaking, deeper coaching after, on your terms.
A real app, fast enough to matter.
Altura is a native macOS and iPadOS app, not a web tool or browser plug-in. Live coaching only works if the signal arrives while you can still use it.
During a session, Altura uses on-device real-time nudge processing to catch meaningful patterns and respond in under one second. Deeper post-session analysis can use local or cloud AI, based on your settings.
Filler clustering detection
Real-time signal accuracy
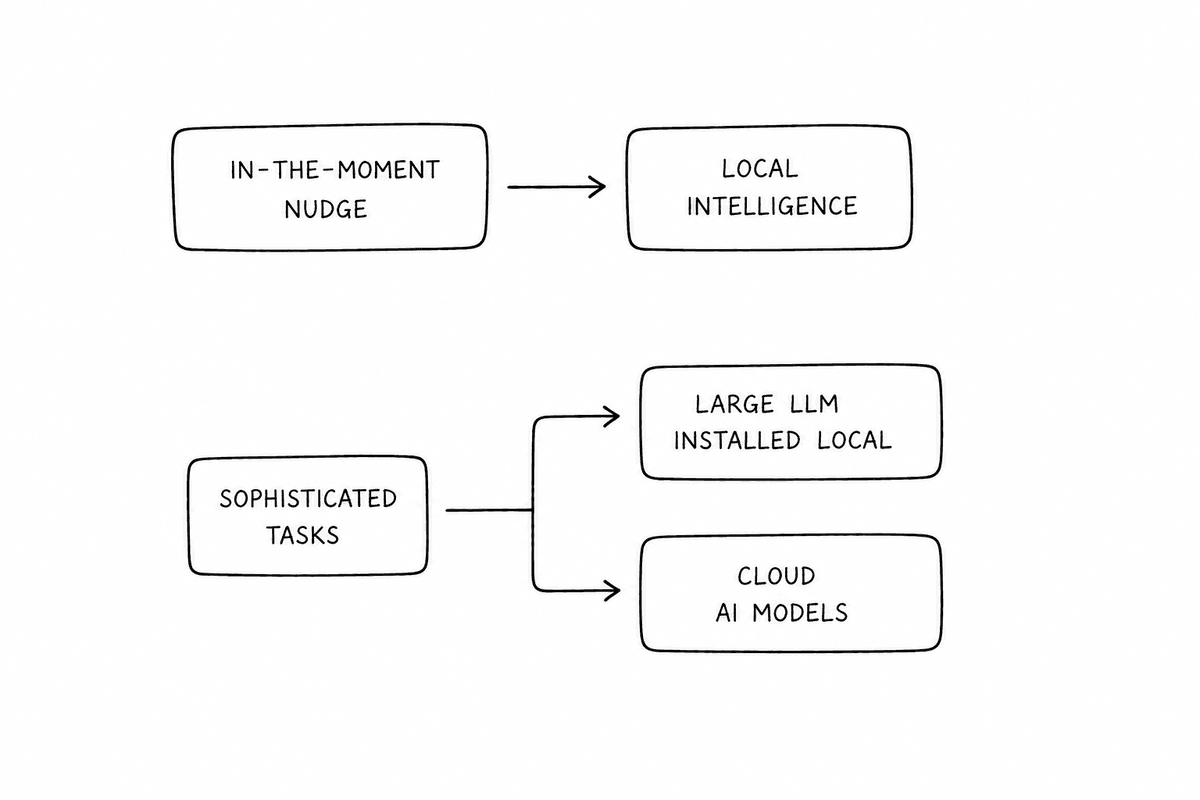
The right AI for each job.
Real-time nudges need speed, so Altura uses on-device local intelligence during the session. More sophisticated coaching can use either a powerful local LLM add-on or cloud AI, depending on the quality and privacy setting you choose.
Every nudge and every piece of feedback is tied to your specific speech context. Altura helps you become the best version of yourself, not a perfect performing robot.
Privacy by architecture, not an afterthought.
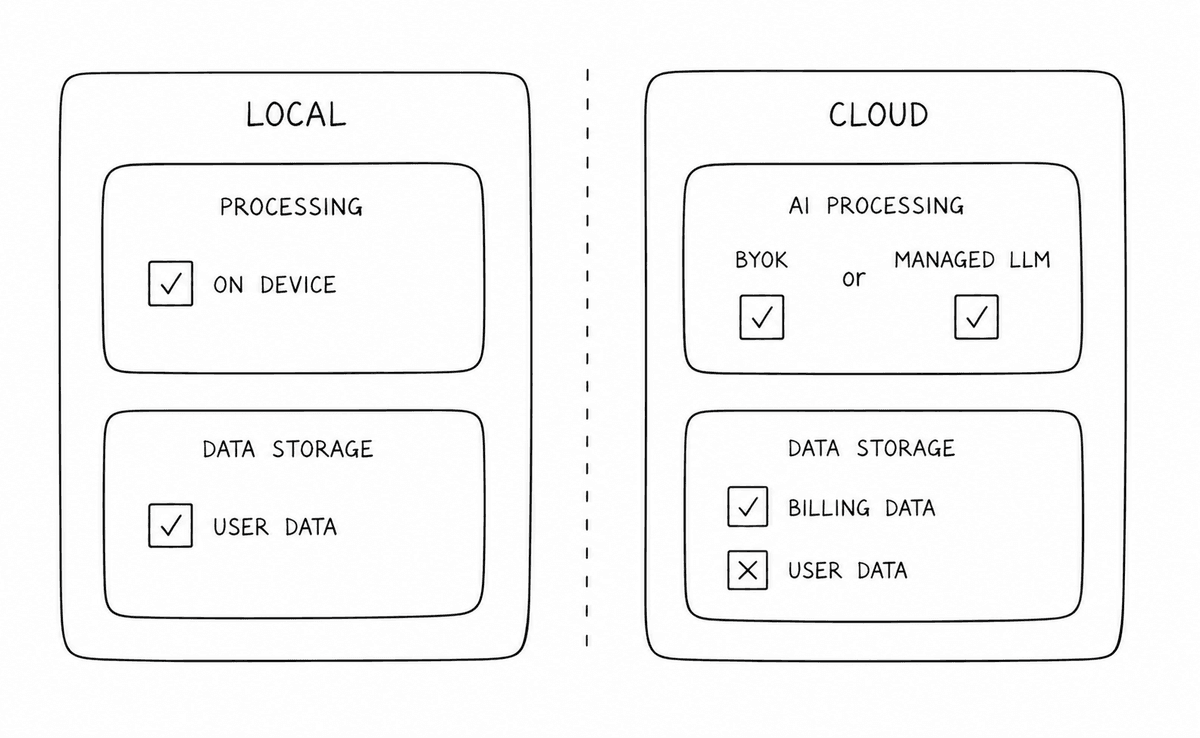
Live audio is processed on your device for real-time coaching. For transcripts and deeper analysis, you choose the privacy model that fits the moment: On-Device, Local LLM, or Cloud AI.
A local LLM add-on keeps deeper analysis on your machine. Cloud AI is available when you want the best performance and convenience, with a bring-your-own-key option for more control. You choose whether and where session data is stored.
Performant, Intelligent, and Private.
See it for yourself.
Take the free assessment. Try the coach. Start getting better.